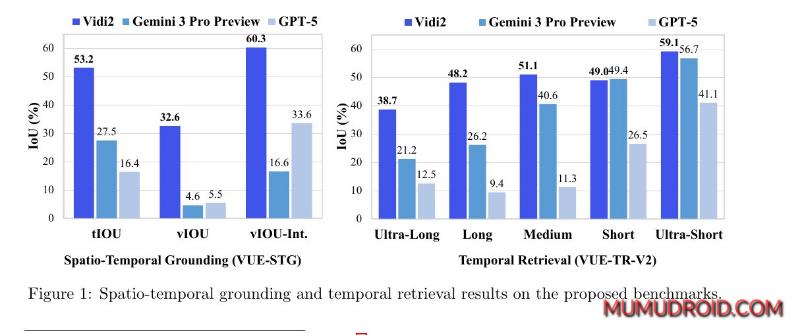
科技巨头字节跳动正式推出一款名为Vidi2的新型AI视频编辑与理解模型。该模型在核心的视频理解能力上表现卓越,据称已超越了谷歌的Gemini Pro等强劲商业模型,尤其在长视频内容解析方面。
Vidi2模型的核心突破在于引入了“时空定位” 能力。当用户输入一段文本查询(例如“找到穿红色衣服的人从门口走到桌前的片段”),Vidi2不仅能精准预测出该事件发生的起止时间点,还能在整个视频片段中,逐帧为特定目标物体生成一个连续的“包围盒”,清晰标示出物体的运动轨迹。
Vidi2的技术底座融合了多模态编码器和一个大型语言模型。它能够同时处理并整合文本、视觉帧序列以及音频信号,从而实现更深层次、更全面的视频内容理解。其训练数据结合了高质量合成剪辑片段与海量的真实世界视频,确保了模型在各种场景下的鲁棒性。
面对视频时长变化极大的挑战——从几秒的短视频到数小时的长视频——Vidi2采用了创新的自适应视觉令牌压缩技术。该技术能动态调整内存占用,确保在处理长视频时不会因内存限制而丢失关键上下文信息,实现了高效与性能的平衡。
Vidi2的发布标志着AI视频理解技术迈上了一个新台阶。其精准的时空定位能力将为视频编辑、内容审核、媒体资产管理、智能安防以及交互式视频体验等领域带来革命性的变化,让机器对动态视觉世界的“阅读”能力无限接近于人类。字节跳动此次的技术突破,无疑在竞争日益激烈的AI视频赛道中,占据了有利位置。