一、前言
近期,Qwen3.5 9B 模型作为阿里云通义千问系列的轻量级大模型引起了广泛关注。9B 参数规模在性能与推理成本之间取得了不错的平衡。为了全面了解该模型在各类场景下的实际表现,我们设计了10个涵盖知识、推理、创作等多个维度的测试用例,对模型进行了系统评测。
二、测试概述
2.1 测试环境
模型版本: Qwen3.5-9B
测试平台: Ollama( 安装命令:ollama run qwen3.5:9b )
测试硬件:英伟达 4090
测试方式: 单轮对话测试
2.2 测试维度
本次测试覆盖以下核心能力(题目来自Github开源作者HanShan006,感谢!):
知识问答能力
逻辑推理能力
语言理解能力
句子生成能力
代码生成能力
翻译能力
数学逻辑与计算能力
情感分析能力
创意联想能力
常识判断能力
三、详细测试结果
3.1 知识问答能力
测试题目: 在《三国演义》里,被诸葛亮用空城计吓退的魏国大将是谁?
预期答案: 司马懿
模型实际回答:
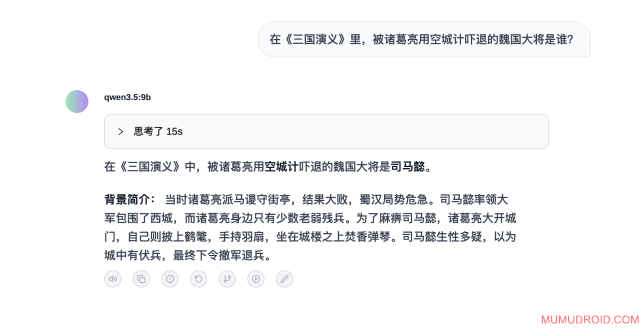
测试分析: 正确
3.2 逻辑推理能力
测试题目: 有三个人,A说B在说谎,B说C在说谎,C说A和B都在说谎。请问谁说真话谁说谎?
预期答案: A和C说谎,B说真话
模型实际回答:
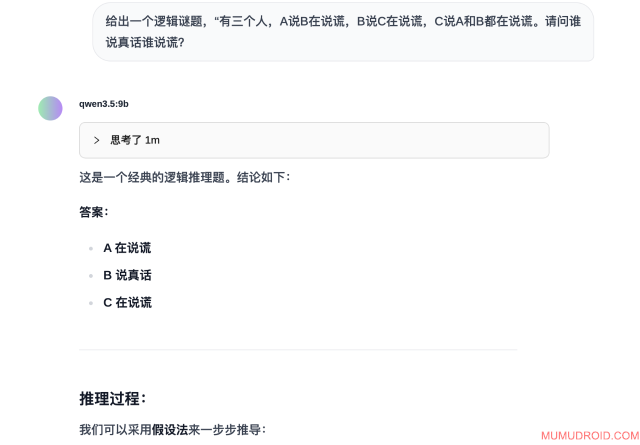
测试分析: 正确
3.3 语言理解能力
测试题目: 解释成语"画蛇添足"的字面意思和比喻意义。
预期答案: 字面意思"画蛇时多画了脚",比喻"做多余的事反而弄巧成拙"
模型实际回答:
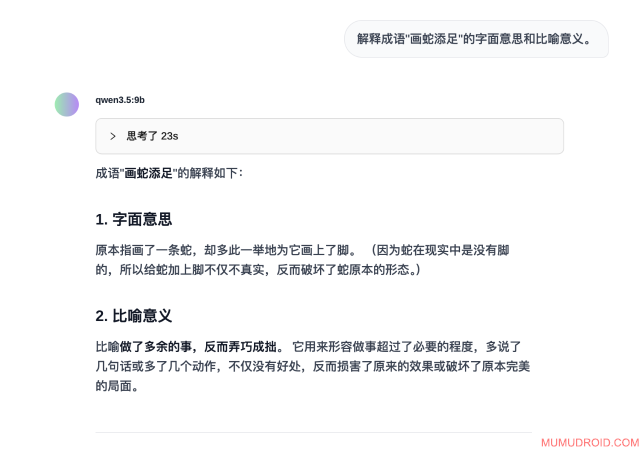
测试分析: 正确
3.4 句子生成能力
测试题目: 以"春天"开头,生成5个不同的完整句子。
预期要求: 生成5个语法正确、内容各异的句子
模型实际回答:
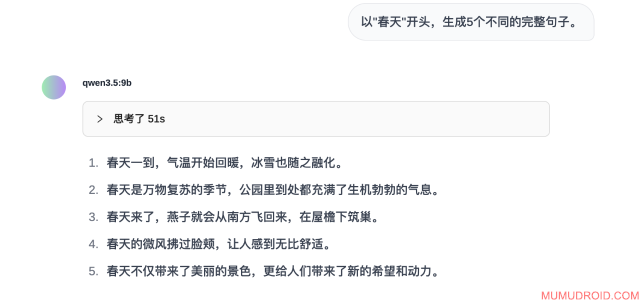
测试分析: 正确
3.5 代码生成能力
测试题目: 编写一个Python程序,实现快速排序算法,并对列表 [5, 3, 8, 4, 2] 进行排序。
预期要求: 生成可运行的快速排序代码并输出正确排序结果
模型回答:
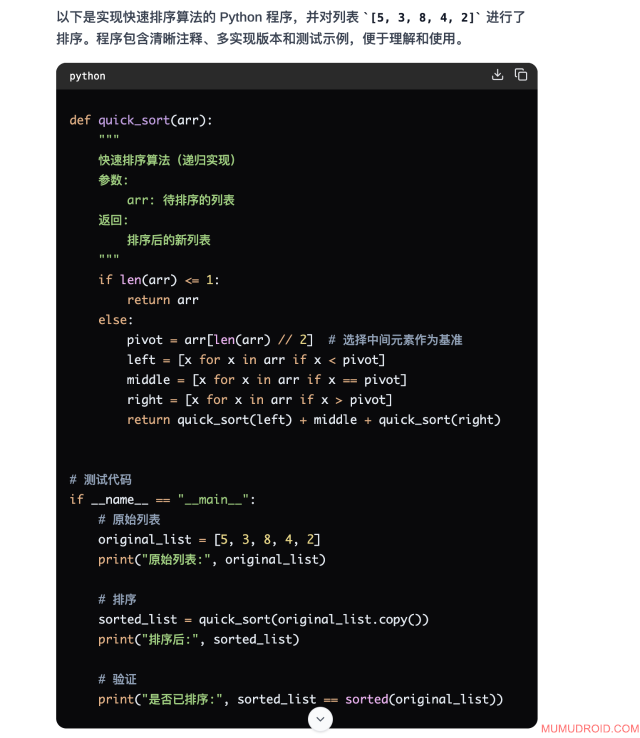
实际执行结果:

测试分析: 正确
3.6 翻译能力
测试题目: 把"不到长城非好汉"翻译成英文。
预期答案: 包含"Great Wall"和"hero/real man"等关键词,如"He who has never been to the Great Wall is not a true hero"
模型实际回答:

3.7 数学逻辑与计算能力
测试题目: 便利店搞促销:买 2 瓶可乐送 1 瓶,每瓶可乐 5 元。小王想给 4 个朋友每人带 1 瓶(包括自己共 5 人),最实惠的买法最少要花多少钱?
预期答案: 最少花费 20 元(买 4 瓶送 2 瓶,实际只需购买 4 瓶即可满足 5 人需求,花费 4×5=20 元)
模型实际回答:

测试分析: 正确
3.8 情感分析能力
测试题目: 判断"我本来以为能中大奖,结果连个安慰奖都没有,真是倒霉透顶了!"这句话的情感倾向。
预期答案: 负面情感
模型实际回答:
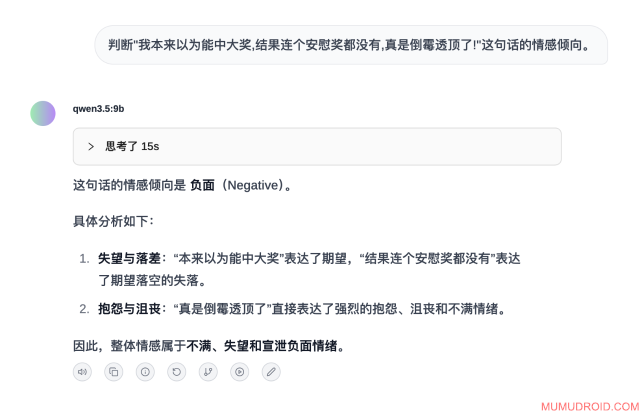
测试分析: 正确
3.9 创意联想能力
测试题目: "如果云朵可以吃,会是什么味道?为什么?"
预期要求: 给出富有想象力和合理性的回答
模型实际回答:

3.10 常识判断能力
测试题目: 骆驼的驼峰储存的是水吗?
预期答案: 不是,骆驼的驼峰主要储存的是脂肪,这些脂肪在代谢时可以转化为水和能量,帮助骆驼在干旱环境中生存,而不是直接储存水。
模型实际回答:

测试分析: 正确
四、测试总结
通过本次10项能力测试,我们对 Qwen3.5 9B 模型有了全面的了解。作为一款轻量级大模型,它的表现相当亮眼,适合部署在资源受限的环境中使用。