在人工智能快速发展的今天,大型语言模型在处理长文本时始终面临着一个根本性限制——上下文窗口的固定令牌数量。这一技术瓶颈导致传统LLM在处理长文档时不仅计算成本急剧上升,性能也大打折扣。而DeepSeek-OCR的横空出世,正为这一难题带来了全新的解决方案。
技术突破:从文本到视觉的巧妙转换
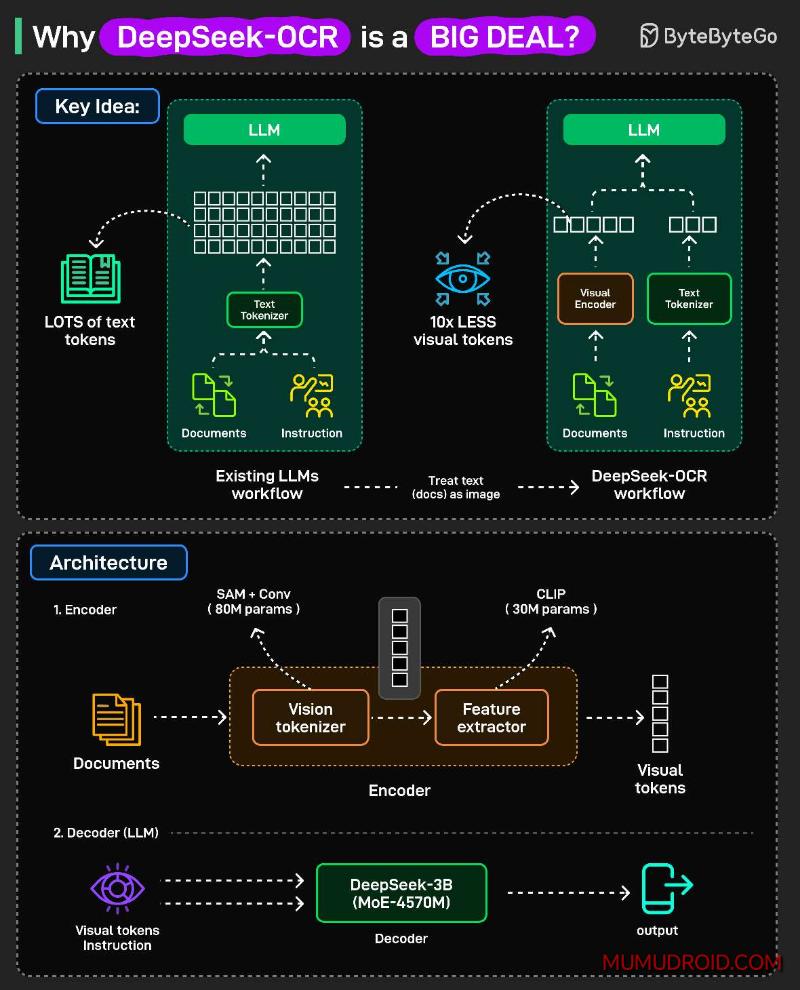
DeepSeek-OCR的核心创新在于其独特的方法论。与传统模型直接将长文本输入LLM不同,该系统首先将文本内容转换为图像格式,随后将这些图像压缩为视觉令牌,最后才将这些视觉令牌传递给语言模型处理。
这一流程的革命性意义在于:通过视觉令牌的中间表示,系统大幅减少了需要处理的令牌数量。更少的令牌意味着注意力机制的计算成本显著降低,同时有效上下文窗口得以大幅扩展,使得聊天机器人和文档模型在处理长内容时既保持强大能力,又提升运行效率。
系统架构:编码器与解码器的精密协作
DeepSeek-OCR的系统架构包含两个关键组件:
编码器负责处理文本图像,提取视觉特征,并将其压缩为少量视觉令牌。这一步骤实现了信息的高效浓缩,为后续处理奠定基础。
解码器采用混合专家语言模型架构,负责读取视觉令牌并逐令牌生成文本。其工作原理类似于标准的仅解码器变换器,但在处理视觉令牌方面进行了专门优化。
应用前景:超越传统OCR的边界
DeepSeek-OCR的技术路径证明,通过视觉表示可以高效压缩文本信息。这一突破使得系统在多个场景中展现出独特价值:
对于超出标准上下文限制的超长文档处理,DeepSeek-OCR提供了完美的解决方案。无论是上下文压缩、标准OCR任务,还是深度解析需求——如将复杂布局的表格和文档结构转换为规整文本,该系统都能胜任。
这一技术不仅为现有文档处理应用带来了性能提升,更为处理超长文本、复杂格式文档的新应用场景开辟了可能性,标志着文档智能处理领域的一个重要里程碑。